Inside a YCAudit run: auditing YedaFlow end-to-end
We pointed YCAudit at our own YedaFlow repo - 101 files, ~10k lines - and let all 14 stages run. Here is what a real audit report looks like, and why every finding ships as a root-caused spec for a coding agent instead of a silent fix.
YCAudit is our codebase auditor - it reads a repository the way a careful senior engineer would, then hands a coding agent a stack of root-caused fix specs. To show what a real run looks like, we pointed it at our own YedaFlow pipeline and let every stage run end to end. No cherry-picking - the same audit we would run on a customer codebase.
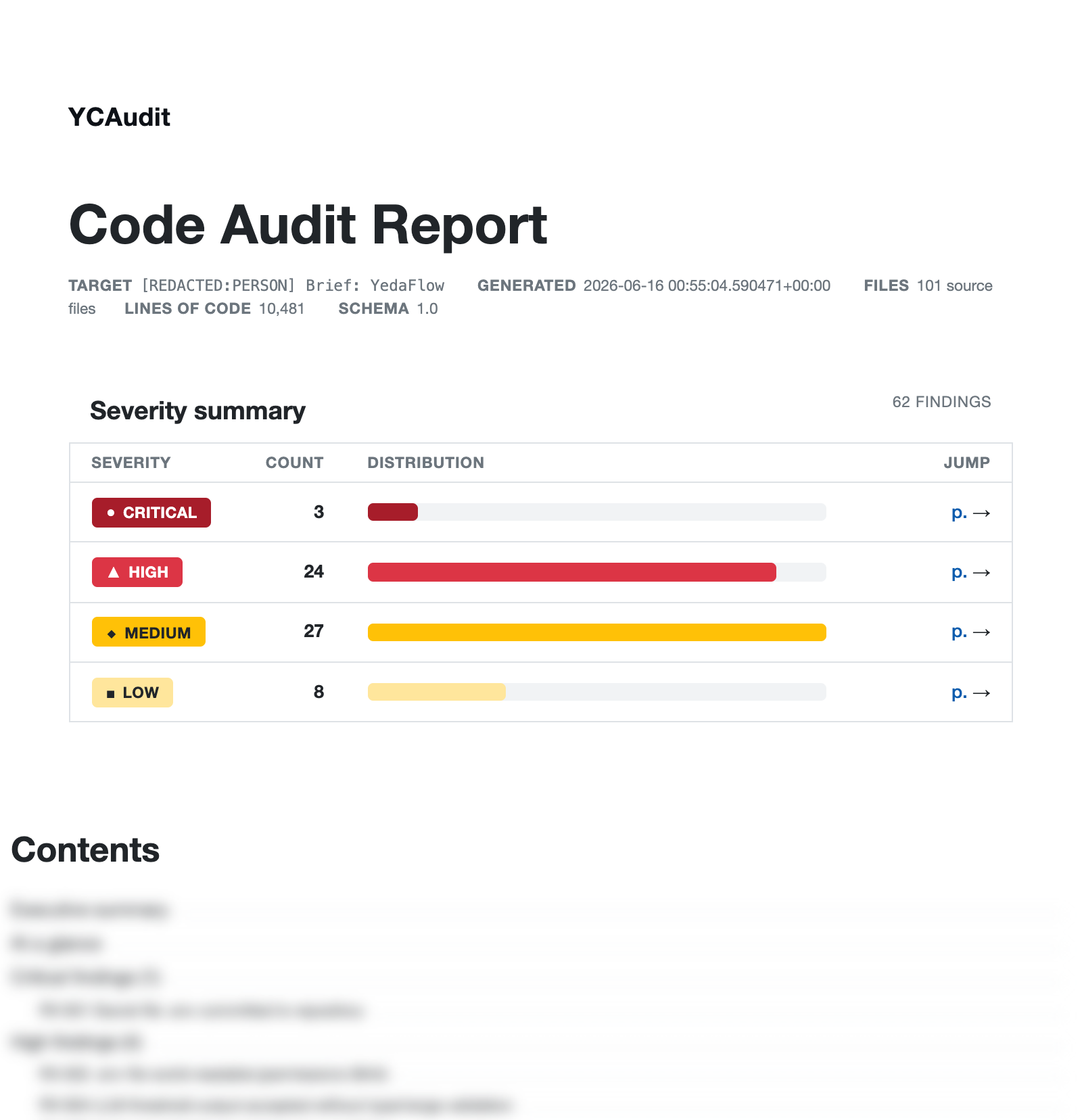 The generated report - cover and severity summary. Individual finding titles are blurred; the full report runs 59 pages.
The generated report - cover and severity summary. Individual finding titles are blurred; the full report runs 59 pages.The target was a real working system: 101 source files, ~10,481 lines of code. All 14 pipeline stages completed, and the rendered report ranked 62 findings by severity, each with a confirmed root cause and a fix spec.
101
Source files10,481
Lines of code14 / 14
Pipeline stages62
FindingsHow a run is structured
The pipeline is four linear stages with a fan-out in the middle. It never jumps straight to a verdict: it builds context first, raises findings across many dimensions, then forces every finding through a root-cause gate before anything is written down.
1. Understand
Reads the repo cold and writes a codebase brief - what the system is, its entry points, data shapes, and the seams worth probing - before a single finding is raised.
2. Review + specialty audits
A core review pass plus parallel lanes for security, performance, QA, architecture, maintainability, AI-codegen, docs, API contracts, data migration, frontend, and runtime verification each surface findings in their own dimension.
3. Investigate
Every candidate finding is run down to a confirmed root cause. The Iron Law of the pipeline: no fix without an explanation of exactly why the bug happens.
4. Spec
Each confirmed issue becomes a precise fix spec plus a reproduction script - a handoff a coding agent can apply - never an in-place edit made by the auditor.
What it found
Across twelve dimensions the run surfaced 62 findings, with the weight in core review, documentation, and security. Two dimensions came back clean - YedaFlow ships no UI surface, and the runtime-verification pass found nothing to flag - which is itself a useful signal: the report says so explicitly rather than going quiet. Even data migration, clean on the earlier pass, this time surfaced an ontology foreign-key gap.
3
Critical
24
High
27
Medium
8
Low
Specs, not silent fixes
The thing that makes the report trustworthy is what YCAudit does not do: it never edits the target. Every confirmed issue ships as a spec - the root cause, the precise change, and a reproduction script - so a human or a coding agent applies the fix with full context and the diff stays reviewable. Symptom-level patches are rejected at the spec stage.
That is the whole point of auditing AI-generated code: the generator already moved fast. The audit's job is to be the slow, skeptical second pass that explains why something is wrong before anyone changes it.